
DataCore mirrored virtual disks full recovery fails repeatedly
Last sunday a customer suffered a power outage for a few hours. Unfortunately the DataCore Storage Server in the affected datacenter weren’t shutdown and therefore it crashed. After the power was back, the Storage Server was started and the recoveries for the mirrored virtual disks started. Hours later, three mirrored virtual disks were still running full recoveries and the recovery for each of them failed repeatedly.
Patrick Terlisten/ vcloudnine.de/ Creative Commons CC0
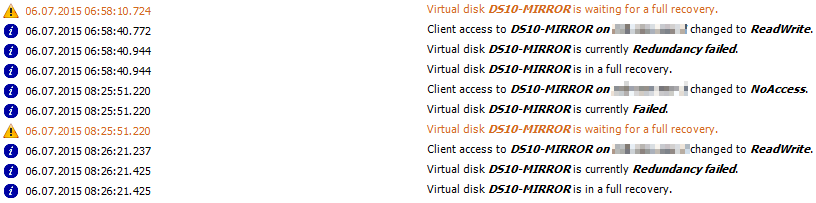
The recovery ran until a specific point, failed and started again. When the recovery failed, several events were logged on the Storage Server in the other datacenter (the Storage Server that wasn’t affected from the power outage):
Source: DcsPool, Event ID: 29
The DataCore Pool driver has detected that pool disk 33 failed I/O with status C0000185.
Source: disk, Event ID: 7
The device, DeviceHarddisk33DR33, has a bad block.
Source: Cissesrv, Event ID: 24606
Logical drive 2 of array controller P812 located in server slot 4 returned a fatal error during a read/write request from/to the volume.
Logical block address 391374848, block count 1024 and command 32 were taken from the failed logical I/O request.
Array controller P812 located in server slot 4 is also reporting that the last physical drive to report a fatal error condition (associated with this logical request), is located in bay 18 of box 1 connected to port 1E
The DataCore support quickly confirmed what we already knew: We had trouble with the backend storage on the DataCore Storage Server that was serving the full recovies for the recovering Storage Server. The full recoveries ran until the point at which a non-readable block was hit. Clearly a problem with the backend storage.
Summary
To summarize this very painful situation:
- VMFS datastore with productive VMs on DataCore mirrored virtual disks with no redundancy
- Trouble with the backend storage on the DataCore Storage Server, that was serving the mirrored virtual disks with no redundancy
Next steps
The customer and I decided to evacuate the VMs from the three affected datastores (each mirrored virtual disks represents a VMFS datastore). To avoid more trouble, we decided to split the unhealthy mirrors. So we had three single virtual disks. After the shutdown of the VMs on the affected datastores, we started a single storage vMotions at a time to move the VMs to other datastores. This worked until the storage vMotion hit the non-readable blocks. The storage vMotions failed and the single virtual disks went also into the status “Failed”. After that, we mounted the single virtual disks from the other DataCore Storage Server (that one, that was affected from the power outage and which was running the full recoveries). We expected that the VMFS on the single virtual disks was broken, but to our suprise we were able to mount the datastores. We moved the VMs from the datastores to other datastores. This process was flawless. Just to make this clear: We were able to mount the VMFS on virtual disks, that were in the status “Full Recovery pending”. I was quite sure that there was garbage on the disks, especially if you consider, that there was a full recovery running that never finished.
The only way to remove the logical block errors is to rebuild the logical drive on the RAID controller. This means:
- Pray for good luck
- Break all mirrored virtual disks
- Remove the resulting single virtual disks
- Remove the disks from the DataCore disk pool
- Remove the DataCore disk pool
- Remove the logical drives on the RAID controller
- Remove the arrays on the RAID controller
- Replace the faulty physical disks
- Rebuild the arrays
- Rebuild the logical drives
- Create a new DataCore disk pool
- Add disks to the DataCore disk pool
- Add mirrors to the single virtual disks
- Wait until the full recoveries have finished
- Treat yourself to a beer
Final words
This was very, very painful and, unfortunately, not the first time I had to do this for this customer. The customer is in close contact to the vendor of the backend storage to identify the root cause.