
HPE StoreVirtual - Managers and Quorum
HPE StoreVirtual is a scale-out storage platform, that is designed to meet the needs of virtualized environments. It’s based on LeftHand OS and because the magic is a piece of software, HPE StoreVirtual is available as HPE ProLiant/ BladeSystem-based hardware, or as Virtual Storage Appliance (VSA) for VMware ESXi, Microsoft Hyper-V and KVM. It comes with an all-inclusive enterprise feature set. This feature set provides
- Storage clustering
- Network RAID
- Thin Provisioning (with support for space reclamation)
- Snapshots
- Asynchronous and synchronous replication across multiple sites
- Automated software upgrades and self-healing storage
- Adaptive Optimization (Tiering)
The license is alway all-inclusive. There is no need to license individual features.
HPE StoreVirtual is not a new product. Hewlett-Packard has acquired LeftHand Networks in 2008. The product had several names since 2008 (HP LeftHand, HP P4000 and since a couple of years it’s StoreVirtual), but the core intelligence, LeftHand OS, was constantly developed by HPE. There are rumours that HPE StoreOnce Recovery Manager Central will be available for StoreVirtual soon.
Management Groups & Clusters
A management group is a collection of multiple (at least one) StoreVirtual P4000 storage systems or StoreVirtual VSA. A management group represents the highest administrative domain. Administrative users, NTP and e-mail notification settings are configured on management group level. Clusters are created per management group. A management group can consist of multiple clusters. A cluster represents a pool of storage from which volumes are created. A volume spans all nodes of a cluster. Depending on the Network RAID level, multiple copies of data are distributed over the storage systems in a cluster. Capacity and IO are expanded by adding more storage systems to a cluster.
As in each cluster, there are aids to ensure the function of the cluster in case of node failes. This is where managers and quorums comes into play.
Managers & Quorums
HPE StoreVirtual is a scale-out storage platform. Multiple storage systems form a cluster. As in each cluster, availability must be maintained if one or more cluster nodes fail. To maintain availability, a majority of managers must be running and be able to communicate with each other. This majority is called “a quorum”. This is nothing new. Windows Failover Clusters can also use a majority of nodes to gain a quorum. The same applies to OpenVMS clusters.
A manager is a service running on a storage system. This service is running on multiple storage systems within a cluster, and therefore in a management group. A manager has several functions:
- Monitor the data replication and the health of the storage systems
- Resynchronize data after a storage system failure
- Manage and monitor communication between storage systems in the cluster
- Coordinate configuration changes (one storage system is the coordinating manager)
This manager is called a “regular manager”. Regular managers are running on storage systems. The number of managers are counted per management group. You can have up to 5 managers per management group. Even if you have multiple storage systems and clusters per management group, you can’t have more than 5 managers running on storage systems. Sounds like a problem, but it’s not. If you have three 3-node clusters in a single management group, you can start managers on 5 of the 6 storage systems. Even if two storage systems fail, the remaining three managers gain a quorum. But if the quorum is lost, all clusters in a management group will be unavailable.
I have two StoreVirtual VSA running in my lab. As you can see, the management group contains two regular managers and vsa1 is the coordinating manager.
Patrick Terlisten/ vcloudnine.de/ Creative Commons CC0
There are also specialized manager. There are three types of specialized managers:
- Failover Manager (FOM)
- Quorum Witness (NFS)
- Virtual Manager
A FOM is a special version of LeftHand OS and its primary function is to act as a tie breaker in split-brain scenarios. it’s added to a management group. It is mainly used if an even number of storage systems is used in a cluster, or in case of multi-site deployments.
The Quorum Witness was added with LeftHand OS 12.5. The Quorum Witness can only be used in 2-node cluster configurations. It’s added to the management group and it uses a file on a NFS share to provide high availability. Like the FOM, the Quorum Witness is used as the tie breaker in the event of a failure.
The Virtual Manager is the third specialized managers. It can be added to a management group, but its not active until it is needed to regain quorum. It can be used to regain quorum and maintain access to data in a disaster recovery situation. But you have to start it manually. And you can’t add it, if the quorum is lost!
As you can see in this screenshot, I use the Quorum Witness in my tiny 2-node cluster.
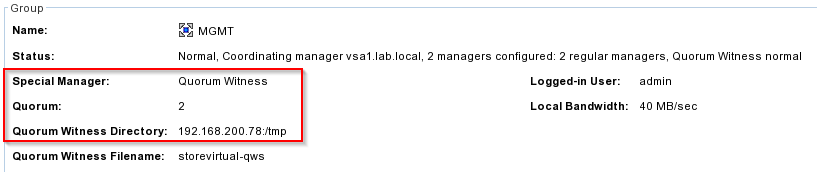
Patrick Terlisten/ vcloudnine.de/ Creative Commons CC0
Regardless of the number of storage systems in a management group, you should use an odd number of managers. An odd number of managers ensures,that a majority is easily maintained. In case of a even number of manager, you should add a FOM. I don’t recommend to add a Virtual Manager.
| # of storage systems | # of Manager |
|---|---|
| 1 | 1 regular manager |
| 2 | 2 regular manager + 1 specialized manager |
| 3 | 3 regular manager or 2 + 1 FOM or Virtual Manager |
| 4 | 3 regular manager or 4 + 1 FOM or Virtual Manager |
| > 5 | 5 regular manager or 4 + 1 FOM or Virtual Manager |
In case of a multi-site deployment, I really recommend to place a FOM at a third site. I know that this isn’t always possible. If you can’t deploy it to a third site, place it at the “primary site”. A multi-site deployment is characterized by the fact, that the storage systems of a cluster are located in different locations. But it’s still a single cluster! This might lead to the situation, where a site failure causes the quorum gets lost. Think about a 4-node cluster with two nodes per site. In this case, the remaining two nodes wouldn’t gain quorum (split-brain situation). In this case, a FOM at a third site would help to gain quorum in case of a site failure. If you have multiple clusters in a management group, balance the managers across the clusters. I recommend to add a FOM. If you have a clusters at multiple sites, (primary and a DR site with remote copy), ensure that the majority of managers are at the primary site.
Final words
It is important to understand how managers, quorum, management groups and clusters are linked. Network RAID protects the data by storing multiple copies of data across storage systems in a cluster. Depending on the chosen Network RAID level, you can lose disks or even multiple storage systems. But never forget to have a sufficient number of managers (regular and specialized). If the quorum can’t be maintained, the access to the data will be unavailable. It’s not sufficient to focus on data protection. The availability of, or more specifically, the access to the data is at least as important. If you follow the guidelines, you will get a rock-solid, high performance scale-out storage.
I recommend to listen to Calvin Zitos podcast (7 Years of 100% uptime with StoreVirtual VSA) and to read Bart Heungens blog post about his experience with HPE StoreVirtual VSA (100% uptime for 7 years with StoreVirtual VSA? Check!).