
Powering on a VM with shared VMDK fails after extending a EagerZeroedThick VMDK
I hope that you are not reading this blog post while searching for a solution for a failed cluster. If so, feel free to leave a comment if this blog post saved your evening or weekend. :)
Last friday, a change at one of my customers went horribly wrong. I was not onsite, but they contacted me during the night from friday to saturday, because their most important Windows Server Failover Cluster was unable to start after extending a shared VMDK.
They tried something pretty simple: Extending an virtual disk of a VM. That is something most of us doing pretty often. The customer did this also pretty often. It was a well known task… Except the fact, that the VM was part of a Windows Server Failover Cluster. With shared VMDKs. And the disks were EagerZeroedThick, because this is a requirement for shared VMDKs.
They extended the disk using the vSphere Web Client. And at this point, the change was doomed to fail. They tried to power-on the VMs, but all they got was this error:
VMware ESX cannot open the virtual disk, “/vmfs/volumes/4c549ecd-66066010-e610-002354a2261b/VMNAME/VMDKNAME.vmdk” for clustering. Please verify that the virtual disk was created using the ’thick’ option.
A shared VMDK is a VMDK in multiwriter mode. This VMDK has to be created as Thick Provision Eager Zeroed. And if you wish to extend this VMDK, you must use vmkfstools with the option -d eagerzeroedthick. If you extend the VMDK using the Web Client, the extended portion of the disk will become LazyZeroed!
VMware has described this behaviour in the KB1033570 (Powering on the virtual machine fails with the error: Thin/TBZ disks cannot be opened in multiwriter mode). There is also a blog post by Cormac Hogan at VMware, who has described this behaviour.
That’s a screenshot from the failed cluster. Check out the type of the disk (Thick-Provision Lazy-Zeroed).
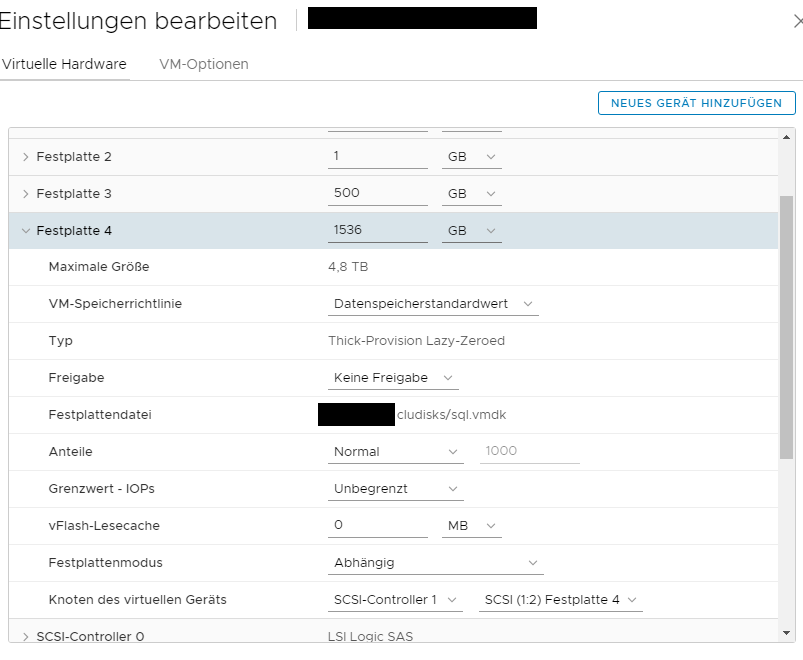
Patrick Terlisten/ vcloudnine.de/ Creative Commons CC0
You must use vmkfstools to extend a shared VMDK - but vmkfstools is also the solution, if you have trapped into this pitfall. Clone the VMDK with option -d eagerzeroedthick.
vmkfstools -i old.vmdk new.vmdk -d eagerzeroedthick
Another solution, which was new to me, is to use Storage vMotion. You can migrate the “broken” VMDK to another datastore and change the the disk format during Storage vMotion. This solution is described in the “Notes” section of KB1033570.
Both ways will fix the problem. The result will be a Thick Provision Eager Zeroed VMDK, which will allow the VMs to be successfully powered on.