
Why I moved from NFS to vSAN... and why it went wrong
I wanted to retire my Synology DS414slim, and switch completely to vSAN. Okay, no big deal. Many folks use vSAN in their lab. But I’d like to explain why I moved to vSAN and why this move failed. I think some of my thoughts are also applicable for customer environments.
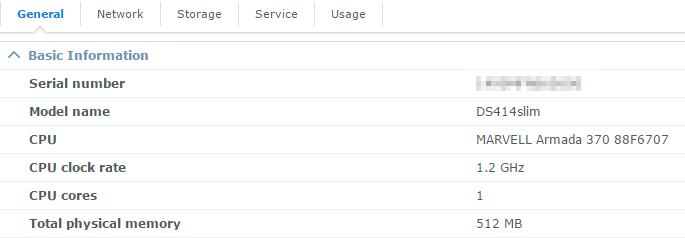
So far, I used a Synology DS414slim with three Crucial M550 480 GB SSDs (RAID 5) as my main lab storage. The Synology was connected with two 1 GbE uplinks (LAG) to my network, and each host was connected with 4x 1 GbE uplinks (single distributed vSwitch). The Synology was okay from the capacity perspective, but the performance was horrible. RAID 5, SSDs and NFS were not the best team, or to be precise, the CPU of the Synology was the main bottleneck.
Patrick Terlisten/ vcloudnine.de/ Creative Commons CC0
1,2 GHz is not enough, if you want to use NFS or iSCSI. I never got more than 60 MB/s (sequential). The random IO performance was okay, but as soon as the IO increased, the latencies went through the roof. Not because the SSDs were to slow, but because the CPU of the Synology was not powerful enough to handle the NFS requests.
Workaround: Add more flash storage
The workaround for the poor random IO performance was adding more flash storage. This time, the flash storage was added to the hosts. I used PernixData FVP to boost my lab. FVP was a quite cool product (unfortunately it was a cool product.) PernixData granted me, as a PernixPro, some licenses for my lab.
End of an era
The acquisition of PernixData by Nutanix, the missing support für vSphere 6.5, and the end of availability of all PernixData products led to the decision to remove PernixData FVP from my lab. Without PernixData FVP, my lab was again a slow train crawling up a hill. Four HPE ProLiant, with enough CPU (40 cores) and memory resources (384 GB RAM) were tied down by slow IO.
Redistribution of resources
I had
- three 480 GB SSDs, and
- three 40 GB SSDs
in stock. The 40 GB SSDs were to small and slow, so I replaced them with 120 GB SSDs. I was able to equip three of my four hosts with SSDs. Three hosts with flash storage were enough to try VMware vSAN.
Fortunately, not all hosts have to add capacity to a vSAN cluster. Hosts can also only consume storage from a vSAN cluster. With this in mind, vSAN appeared to be a way out of my IO dilemma. In addition, using the 480 GB SSDs as capacity tier, a vSAN all-flash config was possible.
Migration
It took me a little time to move around VMs to temporary locations, while keeping my DC and my VCSA available. I had to remove my datastore on the Synology to free up the 480 GB SSDs. The necessary vSAN licenses were granted by VMware (vExpert licenses).
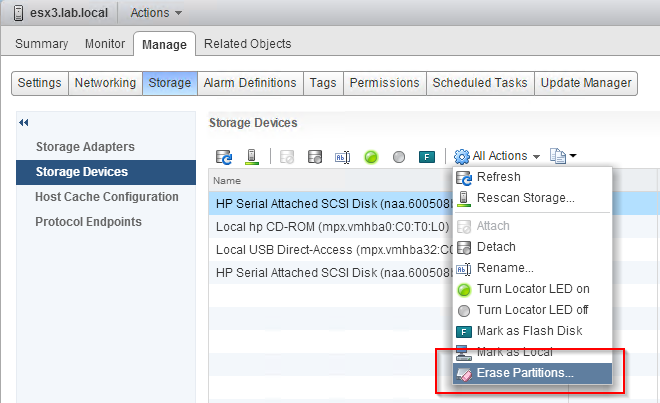
The creation of the vSAN cluster itself was easy. Fortunately, wiping partitions from disks is easy. You can use the vSphere Web Client to do this.
Patrick Terlisten/ vcloudnine.de/ Creative Commons CC0
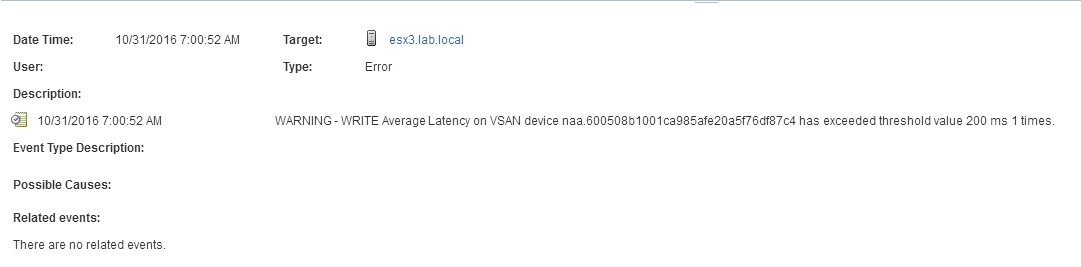
The initial performance was quite good, much better than expected and much better than the NFS performance of the old Synology NAS. I enabled deduplication and compression, but as soon as I moved VMs to the vSAN datastore, the throughput dropped and latencies went through the roof. It was totally unusable. Furthermore, I got health alarms:

Patrick Terlisten/ vcloudnine.de/ Creative Commons CC0
As the load increased, the errors became more severe.
Patrick Terlisten/ vcloudnine.de/ Creative Commons CC0
WARNING – WRITE Average latency on VSAN device %s is %d ms an higher than threshold value %d ms
WARNING – WRITE Average Latency on VSAN device %s has exceeded threshold value %d ms %d times.
I was able to solve this with a blog post of Cormac Hogan (VSAN 6.1 New Feature – Handling of Problematic Disks). Even without compression and deduplication, the performance was not as expected and most times to low to work with. At this point, I got an idea what was causing my vSAN problems.
Do not use consumer-grade hardware with vSAN
To be honest: The budget is the problem. I had to take consumer-grade SSDs.
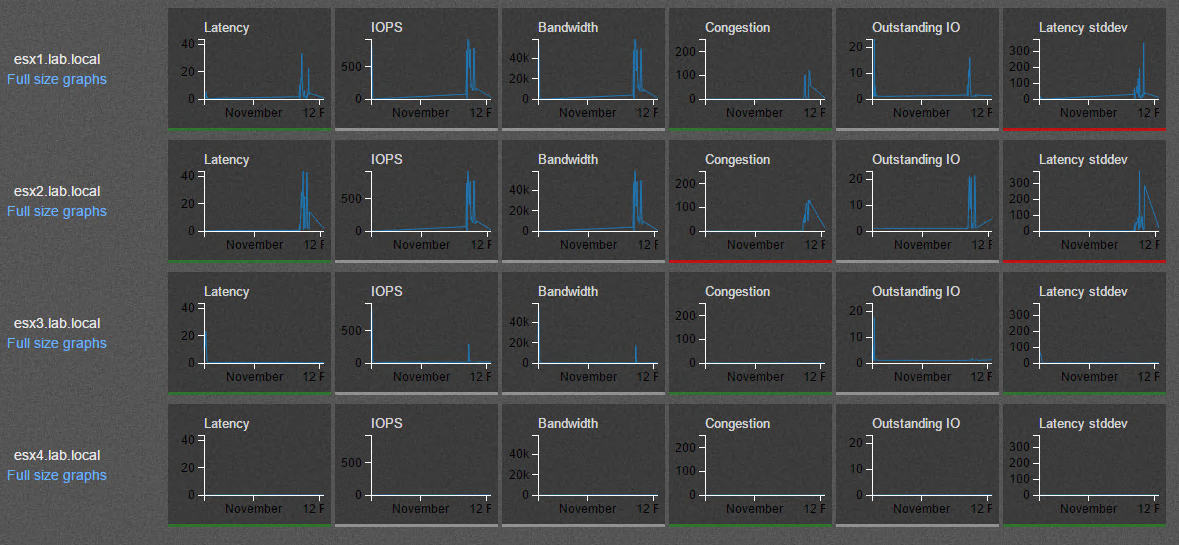
This is a screenshot from the vSAN Observer. esx1 to esx3 are equipped with SSDs, esx4 is only consuming storage from the vSAN cluster.
Patrick Terlisten/ vcloudnine.de/ Creative Commons CC0
Red is not the color to highlight good things…
An explanation attempt
This blog post of Duncan Epping (Why Queue Depth matters!) is a bit older, but still valid in my case. The controller I use (HPE Smart Array P410i) has a a deep queue (1011), the RAID device has a queue length of 1024, but the SATA SSDs have only a queue length of 32. Here’s the disk adapter and disk device view of ESXTOP.
7:32:24am up 2 days 15:56, 777 worlds, 2 VMs, 3 vCPUs; CPU load average: 0.01, 0.01, 0.01
ADAPTR PATH NPTH AQLEN CMDS/s READS/s WRITES/s MBREAD/s MBWRTN/s DAVG/cmd KAVG/cmd GAVG/cmd QAVG/cmd
vmhba0 - 3 1011 4264.32 846.35 3417.97 44.31 61.81 5.06 0.01 5.06 0.00
7:31:51am up 2 days 15:56, 777 worlds, 2 VMs, 3 vCPUs; CPU load average: 0.01, 0.01, 0.01
DEVICE PATH/WORLD/PARTITION DQLEN WQLEN ACTV QUED %USD LOAD CMDS/s READS/s WRITES/s MBREAD/s MBWRTN/s DAVG/cmd KAVG/cmd GAVG/cmd QAVG/cmd
mpx.vmhba32:C0:T0:L0 - 1 - 0 0 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
naa.600508b1001cb6a46f895b4d05ebb2a3 - 1024 - 0 0 0 0.00 150.30 2.29 148.01 0.01 9.25 0.39 0.00 0.39 0.00
naa.600508b1001cfa6875ba9d07c38b1eb2 - 1024 - 0 0 0 0.00 437.16 413.32 23.84 10.22 0.10 0.89 0.00 0.90 0.00
The consumer-grade SSDs drowned in IOs, unable to handle parallel read and write operations. There’s nothing much that I can do. Currently there are two options:
- Replacing the SSDs with devices, that have a deeper queue depth
- Replace the Synology NAS with a more powerful NAS and move back to NFS
I don’t know which way I will go. To get this clear:
- This is my lab, not a customer environment
- It is not a vSAN related problem
- It is because of consumer-grade hardware
Do not try this at production kids. Go vSAN, but please use the right hardware.